Swiggy公司最近通过其实时机器学习排序系统显著提升了其搜索自动补全功能。该系统直接运行在OpenSearch内部,取代了传统的启发式排序方案,避免了引入额外的服务和网络跳转,同时提高了自动补全结果的相关性。该技术特别针对延迟敏感的自动补全请求进行了优化,因为用户每输入一个字符都可能触发一次新的搜索查询。Swiggy的新方案将整个流程拆分为候选生成和排序两个阶段,利用基于嵌入式向量的相似度搜索和词法检索生成更宽泛的候选建议,然后使用机器学习模型根据预测相关性对这些建议进行排序。这种设计不仅提高了速度,还确保了低延迟响应,使系统在大规模场景下仍能维持高效的性能。
--91likeyou---
当用户开始输入时,系统首先借助 OpenSearch 的词法检索,并结合基于嵌入式向量的相似度搜索,生成一组更宽泛的候选建议。该检索层对召回率和响应速度进行了优化。随后,这些候选建议会被送入排序层,由机器学习模型根据预测相关性重新排序。
该排序系统引入了实时信号,例如,用户交互历史、点击行为、查询上下文和条目热度。这些特征会与离线训练好的模型结合,并在线上进行推理。系统使用了一个特征存储同时服务于预计算特征和流式特征,从而在避免高成本实时计算的同时,仍然能够对最新用户行为做出响应。排序层采用与 OpenSearch 集成的学习排序方法进行构建,通常可通过像OpenSearch LTR这样的框架来实现,并使用RankLib等模型家族以及XGBoost这类梯度提升树(gradient boosted tree)方法来完成排序和重排序任务。
该自动补全平台还包含一个持续反馈的闭环,利用实时用户交互数据持续重训排序模型。点击率、转化率以及下单行为会被流式写入离线训练流水线,在那里生成更新后的排序模型,并先存入模型注册表,再部署到线上排序服务中。
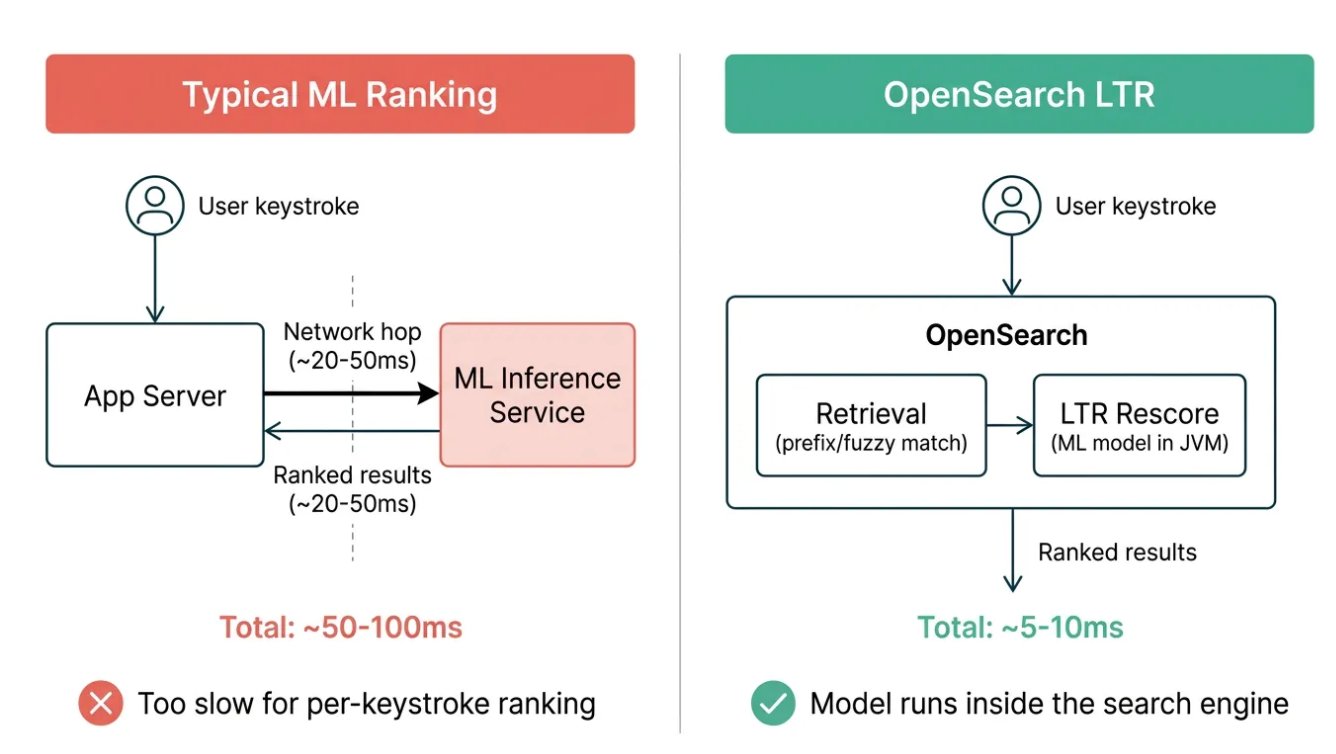
典型机器学习排序服务与 OpenSearch LTR 延迟的对比(来源:Swiggy博客)
该架构的设计目标是满足严格的性能要求。自动补全请求具有高度的交互性,因此必须提供低延迟响应,这也使系统在设计上更偏向轻量模型和优化后的推理路径。系统并没有在线上链路中依赖复杂的深度模型,而是在模型复杂度与服务效率之间取得了平衡,以在大规模场景下维持响应能力。
基于 OpenSearch LTR 的自动补全机器学习模型训练与部署流程(来源:Swiggy博客)
该系统还包含一个反馈闭环,持续收集用户交互并用于改进排序模型。点击率和转化信号会被送入离线训练流水线,使模型能够适应不断变化的用户行为和新出现的查询模式。这使自动补全系统可以在无需手工更新规则的情况下适应新趋势。
Swiggy 工程师表示,该设计将机器学习整合进了一个传统上以规则和检索为主的组件中,同时没有牺牲延迟表现。候选生成与排序的分离,使每个阶段都可以独立优化;而特征存储与流式流水线的使用,则确保了训练环境与服务环境之间的一致性。
查看英文原文: Swiggy Improves Search Autocomplete Using Real Time Machine Learning Ranking
🔥 热词:#OpenSearch · #Swiggy通过实时机器学习排序提升搜索自动补全效果 · #Swiggy · #详细介绍了该公司用于自动补全搜索建议的实时机器学习排序系统架构 · #说明平台如何在严格延迟的要求下 · #检索、特征存储和 · #learning · #to