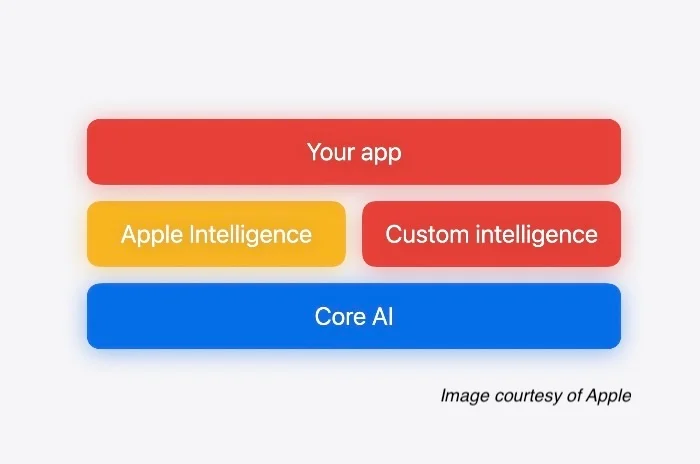
在2026年WWDC大会上,苹果推出了全新的Core AI框架,这是继Core ML之后的官方继任者。该框架旨在让开发者能够完全在设备本地运行大语言模型和生成式AI,同时支持自定义转换后的PyTorch模型和预优化的开源模型。苹果表示,新的Core AI框架提供了一个统一的架构,可在i、iPad、Mac以及Apple Vision Pro上部署小至仅30亿参数的视觉模型、大至最高700亿参数的推理模型。
--91likeyou---
Core AI 是 Apple In 的底层技术,随着苹果下一代操作系统与工具链发布,开发者将可使用该框架打造苹果所称的 “自定义智能功能”。Core AI 只能在 Apple Silicon 上运行,确保用户数据隐私、零服务器依赖,也不会产生按词元计费的云端开销。
Core AI 的关键能力包括:统一硬件访问,工作负载可使用单个 API 在 CPU、GPU 和神经网络引擎上无缝运行;内存安全的 Swift API 可实现零拷贝数据路径和对推理内存的精细控制;提前(AOT)编译技术,将运算预处理工作转移至设备外部完成,实现近乎瞬时的模型加载速度。
如前所述,你可以使用 Core AI PyTorch 将 PyTorch 模型转换为 Core AI 模型。最简单的方法是将 PyTorch 导出为 torch.export.ExportedProgram,然后使用 TorchConverter().add_exported_program(ep).to_coreai() 将其转换为 CoreAI 的 AIProgram。
或者,你可以使用库提供的内置复合算子(如注意力机制、RoPE 嵌入、RMSNorm 和 gather-matmul)基于现有 PyTorch 模型构建新的 Core AI 模型,注册自定义降阶函数以便将新的 PyTorch 算子映射到 Core AI IR,甚至创建自定义 Metal 内核以实现更底层的优化。
转换 PyTorch 模型时,一个关键步骤是针对 Apple 硬件进行压缩部署。该过程应用了量化和调色板化等优化技术,这些技术默认与 Core AI 运行时的执行模式对齐,确保高效的设备端性能。
模型压缩有助于减少模型的内存占用(包括磁盘大小和运行时占用)、降低推理延迟、降低功耗,或同时实现以上全部优化。
运行 AIModel 有一个关键特性:模型会自动特化当前硬件和操作系统版本,这个过程在模型首次加载到模型缓存时完成。因此,首次使用模型的耗时可能比后续长一些。开发者可以通过自定义 SpecializationOptions、访问 AICacheModel 来检查模型是否已可用或删除已缓存的模型,甚至可以在应用组之间共享模型缓存。
随着 Core AI 的推出,苹果为其操作系统上的 ML/AI 提供了三种不同的运行方式:Core ML、Core AI 和 MLX Swift。根据 Hacker News 上的开发者讨论来看,苹果的使用建议是:将 Core ML 用于“经典的非神经网络 ML”,如决策树或表格特征工程;将 Core AI 用于神经网络和 Transformer;将 MLX 用于处理自定义模型权重——尽管可能性能较低。社区反馈还指出,虽然 Core AI “让集成高性能 LLM 变得更加容易”,但其长期价值将取决于“官方 Core AI/社区的未来发展”。
查看英文原文:
🔥 热词:#ioc框架有哪些 · #apple core · #iphone core · #ios core · #iocore · #苹果ai芯片有什么用 · #ioc框架原理 · #ai core x