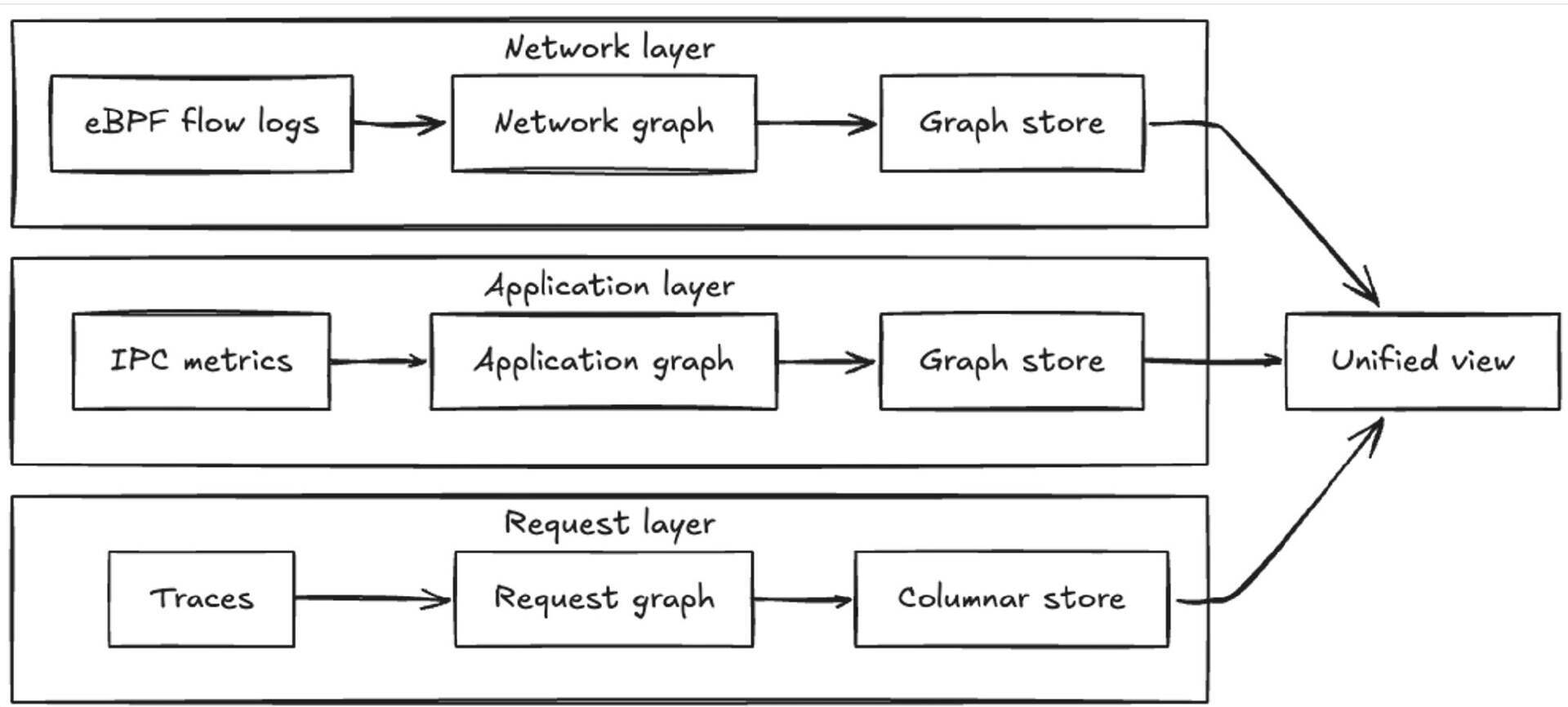
Netflix通过一个内部系统,实时绘制数千个微服务的依赖关系图。该系统集成了三类独立数据源,并实现了近实时的更新,帮助工程师快速解决问题。该系统的动机源于过去四年中在工程支持请求中反复出现的模式。工程师需要知道哪些服务是相互依赖的,以及判断问题是发生在本地还是来自上游依赖。现有的可观测性工具、指标、日志和追踪各自只捕捉了部分信息,但没有提供运行时服务连接的统一视图。Netflix的方法包括从三类事实来源流水线处理、跨区域的 Kafka 消费者、Apache Pekko Streams 运行的图存储构建、gRPC API 暴露拓扑、多跳查询、按可用性等级和业务域过滤,以及亚秒级响应时间作为硬性要求。团队认为这对将依赖关系变化与事件发生时间进行关联非常有帮助。
--91likeyou---
为了解决原始网络流量数据的关键问题,系统采用了一个三阶段的聚合流水线。日志会记录通过负载均衡器和 NAT 网关等中间服务的每一跳,但它们并不能直接展示工程师需要的应用到应用的直接连接。第二阶段执行中间服务的解析,将多跳路径折叠为直接的边。分级的方法分摊了负载,也有助于在某些中间服务流量过大时防止出现热点。
Netflix 方法:三类事实来源
流水线处理是在跨区域的 Kafka 消费者上使用Apache Pekko Streams 来运行的。图存储构建在 Netflix 内部的分布式键值系统之上,并采用专为快速遍历而设计的图数据库层。通过 gRPC API 暴露拓扑,支持多跳查询、按可用性等级和业务域过滤,并将亚秒级(sub-second)响应时间作为硬性要求。
历史查询使用时间窗口聚合而不是保留独立的快照,这样可以在不产生高存储成本的情况下查看过去某一时间点的拓扑。团队认为这对将依赖关系变化与事件发生时间进行关联非常有帮助。
团队指出,一些设计决策来自早期失败尝试的教训。在每天部署多次的环境中,静态或有延迟的依赖映射证明毫无用处。能在小规模下工作的解决方案在 Netflix 的服务数量和流量规模面前会遇到瓶颈。而不完整或不正确的依赖数据反而比没有数据更糟,因为它会在事故中误导工程师得出错误结论。
未来的工作将包括把部署事件和配置变更事件加入拓扑图。从长远来看,团队希望用该图作为自动化根因分析的基础。
Netflix 的这篇文章发布在一个公开工程写作相对稀少的领域。近期,大多数关于服务依赖映射的公开工作,要么止步于 Open 的 Service Graph Connector 能从追踪中推导出的内容,要么把依赖图视为其他事情的基础设施支持,例如,Cloudflare 的 AI 智能体上下文或 Stripe 的指标迁移项目。
至今还没有其他团队以相同深度公开分享如何在这样的规模下构建一个多源、存储于图数据库、近实时的拓扑系统。这要么是因为在 Netflix 这样的服务数量面前该问题确实罕见,要么是因为解决了该问题的团队将其视为竞争优势而将方案保留为内部资料。
查看英文原文:How Netflix Maps Thousands of Microservices in Real-Time
🔥 热词:#netflix微服务架构 · #netflix服务器1 nw-2-5 · #netflix服务区域 · #netflix 服务器 · #微服务网络拓扑图 · #netflix服务范围 · #net 微服务架构 · #netflix微服务组件