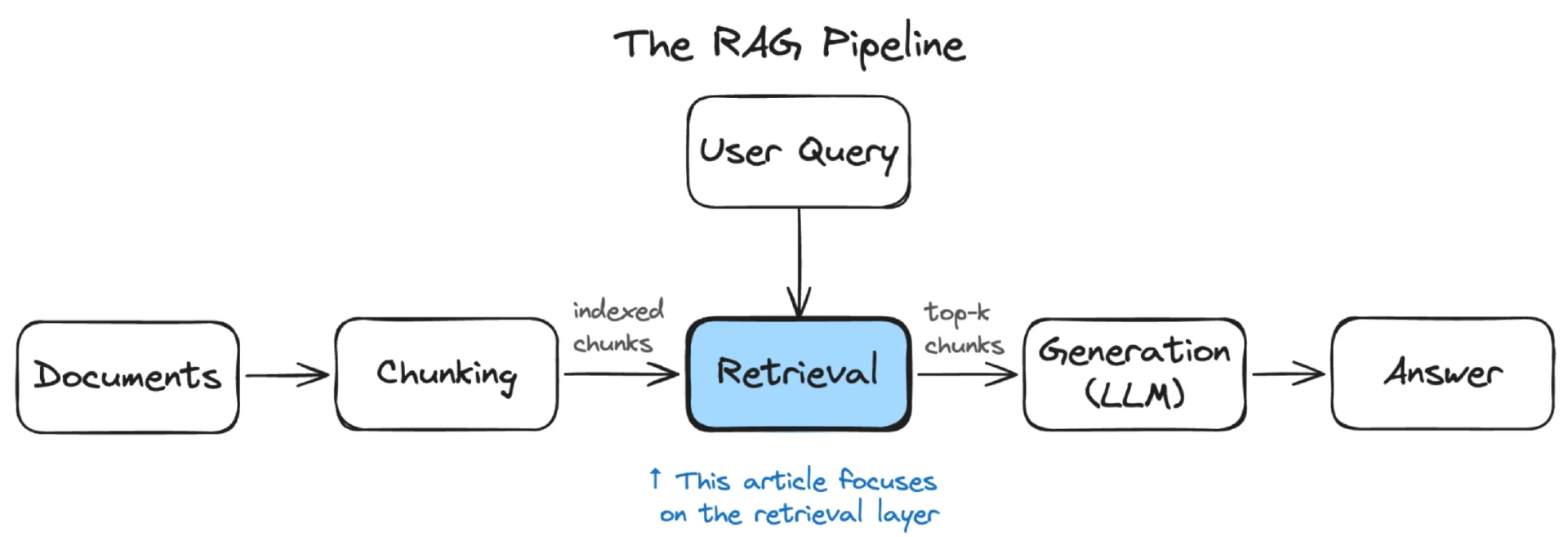
在构建一个内部全能搜索系统的过程中,RAG(检索增强生成)技术被广泛应用于检索公司待办事项、设计文档、发布文档以及运维手册等。然而,向量检索算法(Vector Representation Algorithm, VRA)和嵌入模型(Embedding Model)的固有特性导致了一些问题。向量检索算法通过将文本转换为固定维度的数值向量来捕捉文本的语义信息,而嵌入模型则通过学习文本的语义特征并将其转化为固定维度的向量。尽管这两种方法都能在一定程度上处理相似度较高的文本查询,但它们在面对需要精确匹配的情况时却显得力不从心。例如,当用户查询启用功能标志的运维手册时,由于嵌入模型会为高度相似的文本生成近乎一致的向量,导致检索器难以准确区分,从而错误地推送了禁用相关手册。因此,我们需要一种混合检索的方法来解决这一问题。
--91likeyou---
🔥 热词:#向量检索算法 · #向量空间检索模型匹配算法 · #向量检索框架 · #向量检索库 · #向量检索引擎